不到24小时,开源版Deep Research疯狂来袭!一月少花1400
不到24小时,开源版Deep Research疯狂来袭!一月少花1400昨日,AI 社区最大的新闻当属 OpenAI 发布的全新智能体 Deep Research 了!作为一个使用推理来综合大量在线信息并为用户完成多步骤研究任务的智能体,Deep Research 旨在帮助用户进行深入、复杂的信息查询与分析。
来自主题: AI资讯
9610 点击 2025-02-05 11:34
 搜索
搜索
昨日,AI 社区最大的新闻当属 OpenAI 发布的全新智能体 Deep Research 了!作为一个使用推理来综合大量在线信息并为用户完成多步骤研究任务的智能体,Deep Research 旨在帮助用户进行深入、复杂的信息查询与分析。

孙正义与奥特曼联手宣布,在日成立合资企业「SB OpenAI Japan」。软银每年投入30亿美元,利用OpenAI的技术独家为日本企业提供「Cristal intelligence」定制化AI服务。

2025 年伊始,全球 AI 业界被 DeepSeek 刷屏。当 OpenAI 宣布 5000 亿美元的「星际之门」计划,Meta 在建规模超 130 万 GPU 的数据中心时,这个来自中国的团队打破了大模型军备竞赛的既定逻辑:用 2048 张 H800 GPU,两个月训练出了一个媲美全球顶尖水平的模型。

梁文锋带领着DeepSeek,还在继续搅动大模型行业。继用R1模型炸场之后,1月28日凌晨,除夕夜前一晚,DeepSeek又开源了其多模态模型Janus-Pro-7B,宣布在GenEval和DPG-Bench基准测试中击败了DALL-E 3(来自 OpenAI)和Stable Diffusion。
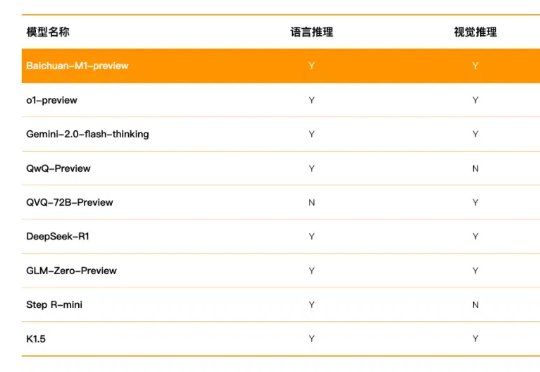
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。

赶在放假前,支棱起来的国产 AI 大模型厂商井喷式发布了一大堆春节礼物。前脚 DeepSeek-R1 正式发布,号称性能对标 OpenAI o1 正式版,后脚 k1.5 新模型也正式登场,表示性能做到满血版多模态 o1 水平。

马斯克和 OpenAI CEO Sam Altman 又双叒叕吵了起来。
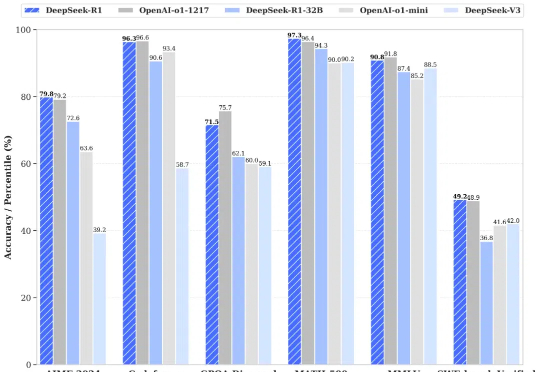
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网: R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 R1 上线 API,对用户开放思维链输出 R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini

10 个月前,闫俊杰也接受过《晚点》访谈,那时他提了 16 次字节、47 次 OpenAI,8 次 Anthropic。这次再聊,他主动提字节少了,提 Anthropic 多了。这与行业风向形成微妙的反差。

昨天,我们报道了一个行业猜想,说是 OpenAI 和 Anthropic 等前沿大模型公司可能已经训练出了下一代大模型,但由于它们的使用成本过高,所以短时间内根本不会被放出来。